|
 DEPTH SHIFT BASICS
DEPTH SHIFT BASICS
Individual log curves are often off-depth with respect to each
other. The problem is worse for older logs, because it may have
taken several runs into the wellbore to obtain all the log curves
required. Modern logs can also suffer from this problem due to mis-typed
parameters in the logging software or logging speed changes. Even if
the log was on-depth to begin with, the data we use may be "second
hand", that is not the original digital data, but digitized manually
or semi-automatically from paper copies.
Shifts are made with respect to a reference curve.
The choice of the reference
curve is somewhat arbitrary but the first choice is often the gamma
ray log, as it is the most common correlation curve. Resistivity is
sometimes preferred. If a curve needs a shift, it is likely that all
curves recorded on that logging run will need the same shift. For
example, if the GR curve on a density neutron log is used as a
reference and a resistivity curve is off-depth relative to this GR,
then all the resistivity curves and the SP probably need the same
shift.
There are numerous other kinds of edits that may be needed. Some
examples are curve re-scaling or normalization, SP base line
straightening, eliminating overlaps and bottom hole effects, filling
gaps, and patching bad data. These are aided by appropriate editing
functions in most software. A little common sense and observation of
offset logs will be useful too.
BLOCK or BULK SHIFT
There are two styles of depth shifting in most commercial software
packages. The block shift moves a portion of a log curve up or down
by a fixed amount. If the top and bottom boundary of the block are
close in intervals with relatively constant log readings, the result
at the boundaries of the block will not look too ugly. It is often
used to place core gamma ray or core porosity and permeability on
depth with log data.
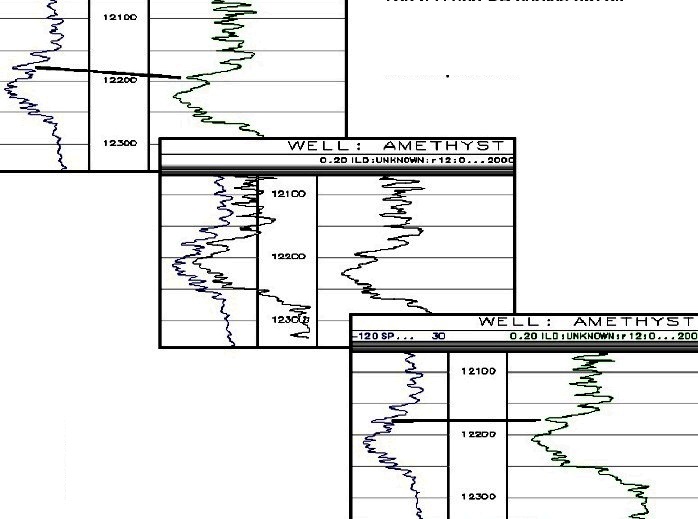
Example of a Block Shift: top left shows correlation line between
two curves, middle shows proposed shift, bottom shows final result.
STRETCH and SQUEEZE SHIFT
The better
method is to stretch and squeeze the log curves using some form of
interpolation to obtain new data points at each data level that fit
the original curve shape. The procedure is usually to pick peaks
and/or valleys (or obvious bed boundaries) on two curves with a
mouse click, where it is assumed that these points should be at the
same depth. After picking enough such points, the software is asked
to perform the interpolation. It can be undone and redone until
satisfied.
Some software packages perform stretch and squeeze automatically
using various forms of cross-correlation between the curves.
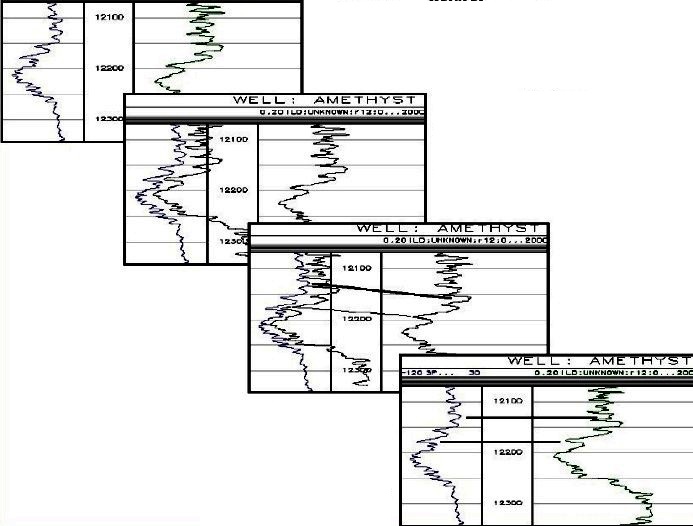
Example of a Stretch and
Squeeze Shift: top left shows correlation lines between two curves,
middle shows proposed shifts, bottom right shows final result.
|

